Оптимизация WEB сервиса Melbis
Практический пример решения задачи оптимизации WЕВ-сервиса, который по словам пользователя "падает и тормозит".
Прикладная система: Melbis Shop 6.1.1 Работают 2 сервера в связке:
MB: Gigabyte H81M-DS2V CPU:Intel(R) Core(TM) i3-4170 CPU @ 3.70GHz, 4 ядра. RAM: 16GB; Net: eth0: RTL8168evl/8111evl 1GB на внешний IP, eth1 Intel(R) PRO/1000 внутренний (192.168.0.0/24) HDD:
$ df -h
Filesystem Size Used Avail Use% Mounted on
/dev/md1 894G 566G 283G 67% /
tmpfs 7.8G 0 7.8G 0% /dev/shm
/dev/md0 772M 146M 570M 21% /boot
/dev/sdc1 106G 3.8G 97G 4% /ssd01 <<< SSD
tmpfs 2.0G 1.6G 428M 80% /tmpfs
$ cat /proc/mdstat
Personalities : [raid1]
md0 : active raid1 sda1[0] sdb1[1]
819136 blocks super 1.0 [2/2] [UU]
md1 : active raid1 sdb2[1] sda2[0]
952188928 blocks super 1.1 [2/2] [UU]
bitmap: 2/8 pages [8KB], 65536KB chunk
#
/dev/sda - Hitachi Ultrastar A7K2000
/dev/sdb - Hitachi Ultrastar A7K2000
# hdparm -tT /dev/md1
Timing cached reads: 11260 MB in 2.00 seconds = 5633.72 MB/sec
Timing buffered disk reads: 350 MB in 3.08 seconds = 113.72 MB/sec
Soft: CentOs 6.7 Nginx 1.10.0 Apache 2.2.22 Php 5.4.45 ISP Panel
MB: Intel DH61WW CPU: Intel(R) Core(TM) i5-3570K CPU @ 3.40GHz, 4 ядра. RAM: 8GB; Net: eth0:Intel(R) PRO/1000 GB на внешний IP, eth1:Intel(R) PRO/1000 GB внутренний (192.168.0.0/24)
HDD:
-bash-4.1# df -h
Filesystem Size Used Avail Use% Mounted on
/dev/sda2 106G 25G 77G 25% /
tmpfs 3.8G 0 3.8G 0% /dev/shm
/dev/sda1 976M 91M 835M 10% /boot
#
/dev/sda = INTEL SSDSC2BW120H6
#
# hdparm -tT /dev/sda2
Timing cached reads: 19040 MB in 2.00 seconds = 9531.36 MB/sec
Timing buffered disk reads: 720 MB in 3.00 seconds = 239.80 MB/sec
Soft: CentOs 6.7 MySQL 5.5.48 ISP Panel
База данных на сервер одна. Тип таблиц MyISAM, 95 таблиц, Записей 6530002, Размер 3.1 GB.
+--------------------------------+------------+
| table_name | table_rows |
+--------------------------------+------------+
| ms_user_log | 3567425 |
| ms_client_field_value | 1125806 |
| ms_order_client_field | 277299 |
| ms_files_store | 244015 |
| ms_store_info | 235064 |
| ms_topic_store | 163000 |
| ms_order_option_set | 151254 |
| ms_tws_search | 132741 |
| ms_client | 108638 |
| ms_store | 57002 |
| ms_u_info_value | 54582 |
| ms_order_store | 33918 |
| ms_order_store_option | 30381 |
| ms_order_version | 25209 |
| ms_orders | 25190 |
| ms_tmp_client | 21292 |
| ms_store_set | 17478 |
| ms_tmp_store | 10141 |
| ms_info_value | 4901 |
| ms_u_store_info | 3832 |
| ms_store_comment | 3755 |
| ms_tws_waitlist | 3187 |
| ms_topic | 3044 |
| ms_u_topic_store | 2206 |
| ms_files_topic | 1975 |
| ms_u_files_store | 1756 |
| ms_u_store | 1100 |
| ms_brand | 890 |
| ms_alt_topic | 866 |
+--------------------------------+------------+
Nginx отдает статический контент, Apache - обрабатывает динамику. Используется отдельный домен i.domain.com для изображений. Находится на этом же сервере. Сервер MySQL открывает порт 3306 только на внутреннем интерфейсе.
Проблема №1
Описание: Nginx отваливать с ошибкой 502, 504 примерно 1 раз в 10-15 минут. Заказчик лечит проблему перегружая службу httpd.
На сервере с "живой" проблемой увидили такое количество процессов httpd:
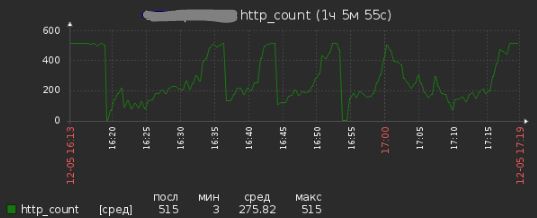 Пик в 515 = отказ Nginx, падение в 0 - перезагрузка службы httpd.
Пик в 515 = отказ Nginx, падение в 0 - перезагрузка службы httpd.
У проекта Melbis Shop нашлось 7 задач в crontab (/var/spool/cron/root):
# время и значения приведены для примера
*/5 * * * * /usr/bin/wget -qO- http://domain.com:81/cron.php?exp=value1 >/dev/null 2>&1
*/5 * * * * /usr/bin/wget -qO- http://domain.ua:81/cron.php?exp=value2 >/dev/null 2>&1
Суть выполняемых задач не известно, но на лицо была переодичность - с которой "падает сервер" (с) заказчик. Сколько длится выполнение одной задачи - не понятно.
Шаг 1. 1. Разнесли время задач крона на 10 минут друг от друга.2 2. Попросили разработчика (через заказчика) вывести в лог время запуска и окончания каждой задачи.
Показания после шага 1 в тот же день:
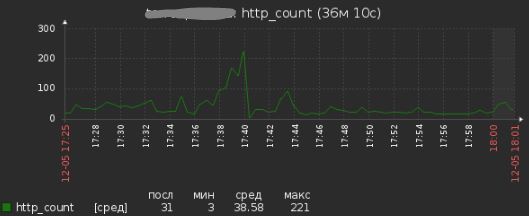
Шаг 2. 1. После общения с заказчиком исключили Apache из запуска скриптов крона, перейдя на PHP.
2 * * * * /var/www/domain.com/cron.sh value1 >/dev/null 2>&1
*/15 * * * * /var/www/domain.com/cron.sh value2 >/dev/null 2>&1
2. Заставили Nginx подождать динамику от Apache немного дольше
# /etc/nginx/conf
server {
server_name domain.com;
...
proxy_connect_timeout 300s;
proxy_send_timeout 300s;
proxy_read_timeout 300s;
...
}
3. Получили время запуска и окончания задач в кроне в логе. Подтвердили предположение, что задачи перекрывали по времени друг-друга. Росло время ответа одного процесса, за ним росло количество процессов httpd (которые видел заказчик). В конце Nginx отключался оп настройке timeout
В последствии, оказалось очень правильно, так как выполнение процессов реально подтормаживали и из-за запросов MУSQL.
Проблема №2
Описание: Спуста 3 дня заказчик зафиксировал 502 ошибку Nginx.
Смотрим на мониторинг и видим что глобально все хорошо. Замечаем не большое увеличение параметра iowait. Присматриваемся к процессу:
$ iotop
Total DISK READ: 0.00 B/s | Total DISK WRITE: 0.00 B/s
TID PRIO USER DISK READ DISK WRITE SWAPIN IO> COMMAND
1542 be/3 root 0.00 B/s 0.00 B/s 0.00 % 99.49 % [jbd2/sdc1-8]
2048 be/4 memcache 0.00 B/s 0.00 B/s 0.00 % 0.00 % memcached ...
1 be/4 root 0.00 B/s 0.00 B/s 0.00 % 0.00 % init
2 be/4 root 0.00 B/s 0.00 B/s 0.00 % 0.00 % [kthreadd]
Процесс jbd2/sdc1 на 99% Висит несколько секунд. Этого оказалось вполне достаточно, чтобы nginx отдал ошибку 502.
Точка монтирования /ssd01 используется для размещение кеша pagespeed nginx. Подумали и решили не "играться" с SSD на боевом сервере, а так как памяти на сервер хватало размещение кеша было перенесено на раздел /tmpfs.
99% загрузка iowait прекратилась, так как прекратилась запись на этот раздел. График загрузки SSD стал вглядеть:
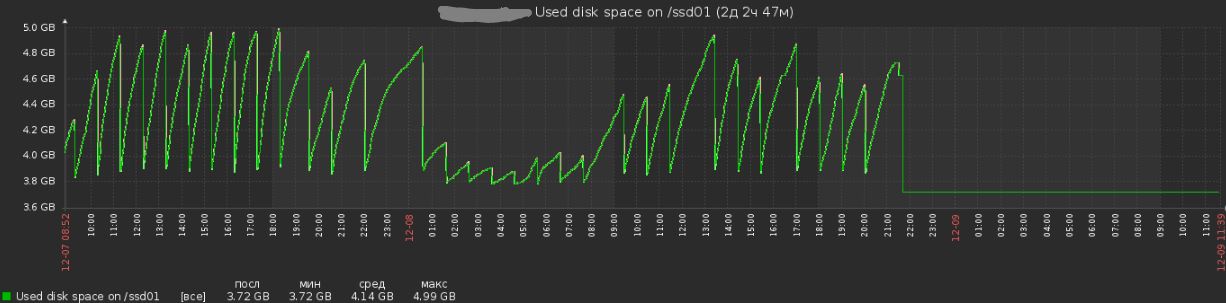
Проблема №3
Описание: Заказчик обратил внимание на торможение в системе примерно в 17:15. Подключили снова мониторинг. Рассматриваем показатели. Видим очень большую загрузку CPU на сервере БД при не выдающемся количестве Query per second.
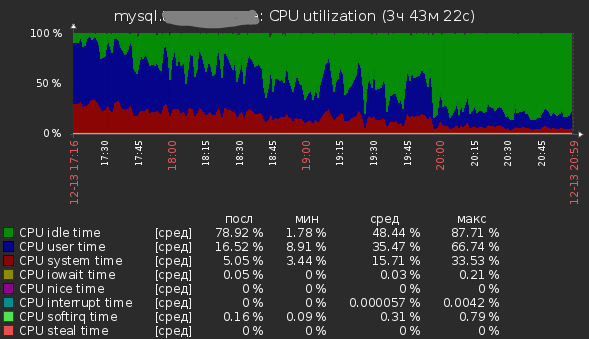
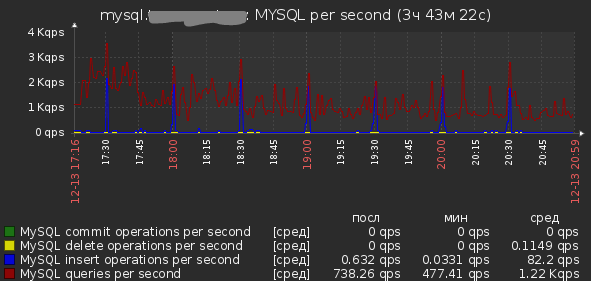 Ничего не исправляли, загрузка CPU понемногу спадала.
Ничего не исправляли, загрузка CPU понемногу спадала.
Примерно в 02:10 включили log_slow_queries на сервере MYSQL. Установили:
Примерно 17:00 следующего дня, снова начался всплеск загрузки CPU. Смотрю на запросы попадающие в slow-queries.log. На глаз выбираю наиболее частые - тестирую. Очень много запросов построены на таблицах, в которых кроме PRIMARY индекса на поле ID нет других. Не знаю был ли другие индексы в этих таблицах, или так получилось... но :)
Некоторые интересные цифры и факты из slow-queries.log:
-----------------
# Query_time: 6.560914 Lock_time: 0.001897 Rows_sent: 18418 Rows_examined: 113829
# Query_time: 6.042265 Lock_time: 0.000017 Rows_sent: 3553202 Rows_examined: 3553202
# Query_time: 22.716306 Lock_time: 0.000236 Rows_sent: 31185 Rows_examined: 60824450
-----------------
# Query_time: 0.025933 Lock_time: 0.000038 Rows_sent: 1 Rows_examined: 108456
SELECT * FROM ms_client WHERE login='XXXXXX' AND pass='XXXXX';
-----------------
# Query_time: 0.150510 Lock_time: 0.000022 Rows_sent: 0 Rows_examined: 57000
UPDATE ms_store how = 0 status_key = 'kAbsent';
-----------------
# Query_time: 0.129256 Lock_time: 0.000035 Rows_sent: 0 Rows_examined: 57000
SELECT status_key FROM ms_store WHERE price =0;
# без индекса
id select_type table type possible_keys key key_len ref rows Extra
1 SIMPLE ms_store ALL NULL NULL NULL NULL 57000 Using where
# Добавлен индекс
id select_type table type possible_keys key key_len ref rows Extra
1 SIMPLE ms_store ref price price 5 const 815
После добавления 15-20 индексов в таблицы, на основании запросов найденных в slow-queries.log Красной стрелкой примерно отмечен момент добавления.
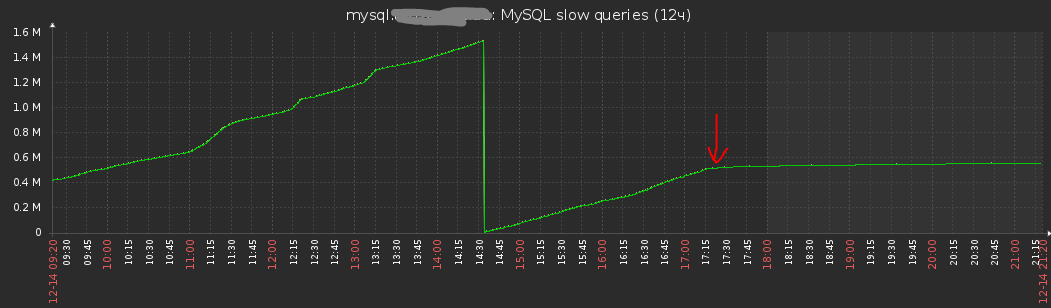
Не все медленные (не индексированные запросы) возможно исправить добавление индексов. Поэтому в какие-то моменты загрузка CPU увеличивается, но сервис исправно работает. Дальнейшая оптимизация запросов нашими силами уже не возможна. К разработчику не обращались - заказчик не просил.
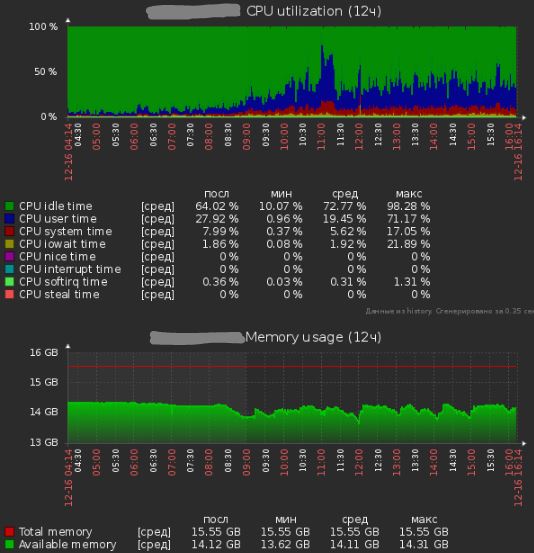
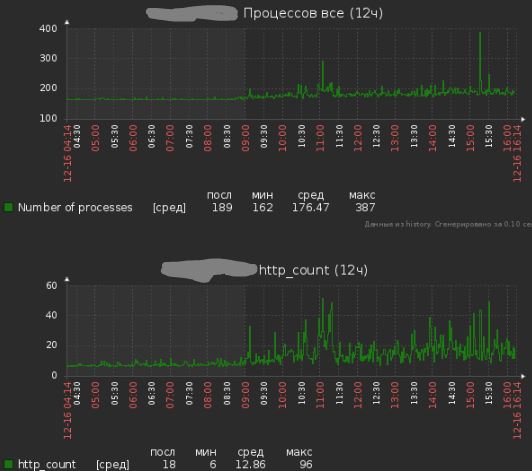
Показания работы сервера после всех исправлений:
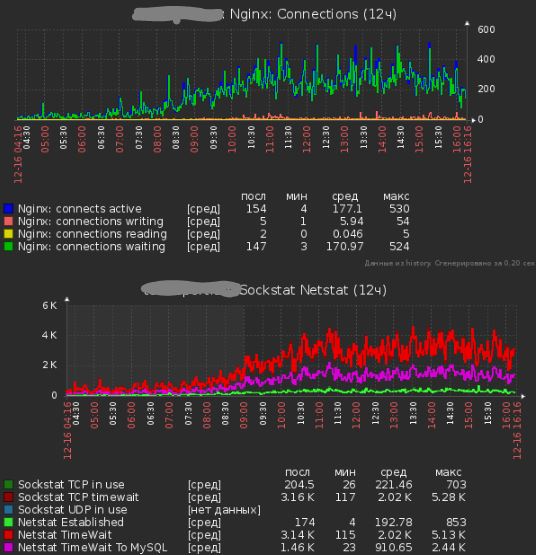
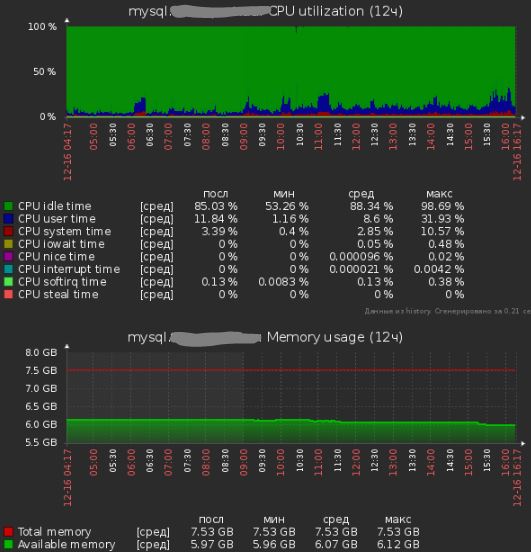
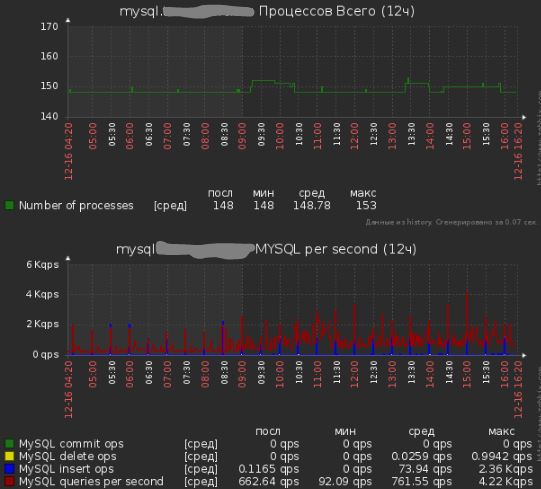
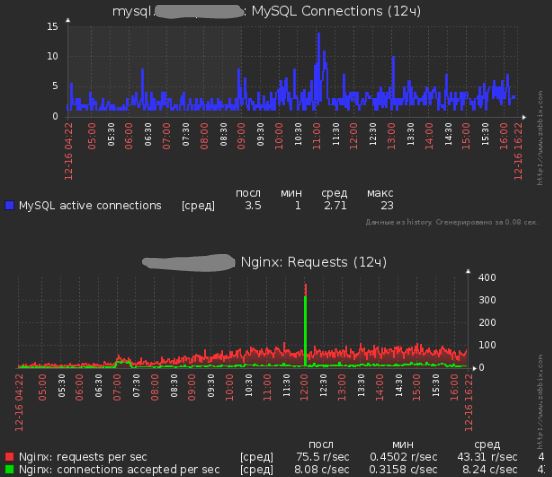
Проблема №4
2017-03-02 23:06 mysql temp - moved to tmpfs